k8s Paas实战——Promtheus监控
Promtheus的特点:
- 多维数据模型:由度量名称和键值对标识的时间序列数据
- 内置时间序列数据库:TSDB
- promQL:一种灵活的查询语言,可以利用多维数据完成复杂查询
- 基于HTTP的pull(拉取)方式采集时间序列数据
- 同时支持PushGateway组件收集数据
- 通过服务发现或静态配置发现目标
- 支持作为数据源接入Grafana
官方架构图

Prometheus Server:服务核心组件,通过pull metrics从 Exporter 拉取和存储监控数据,并提供一套灵活的查询语言(PromQL)。
pushgateway:类似一个中转站,Prometheus的server端只会使用pull方式拉取数据,但是某些节点因为某些原因只能使用push方式推送数据,那么它就是用来接收push而来的数据并暴露给Prometheus的server拉取的中转站,这里我们不做它。
Exporters/Jobs:负责收集目标对象(host, container…)的性能数据,并通过 HTTP 接口供 Prometheus Server 获取。
Service Discovery:服务发现,Prometheus支持多种服务发现机制:文件,DNS,Consul,Kubernetes,OpenStack,EC2等等。基于服务发现的过程并不复杂,通过第三方提供的接口,Prometheus查询到需要监控的Target列表,然后轮训这些Target获取监控数据。
Alertmanager:从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对方的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty 等。
UI页面的三种方法:
- Prometheus web UI:自带的(不怎么好用)
- Grafana:美观、强大的可视化监控指标展示工具
- API clients:自己开发的监控展示工具
工作流程:Prometheus Server定期从配置好的Exporters/Jobs中拉metrics,或者来着pushgateway发过来的metrics,或者其它的metrics,收集完后运行定义好的alert.rules(这个文件后面会讲到),记录时间序列或者向Alertmanager推送警报。
Prometheus交付
交付kube-state-metric
kube-state-metric为prometheus采集k8s资源数据的exporter,能够采集绝大多数k8s内置资源的相关数据,例如pod、deploy、service等等,同时它也提供自己的数据,主要是资源采集个数和采集发生的异常次数统计。
-
在200机器上下载镜像:
[root@hdss7-200 ~]# docker pull quay.io/coreos/kube-state-metrics:v1.5.0 [root@hdss7-200 ~]# docker images|grep kube-state [root@hdss7-200 ~]# docker tag 91599517197a harbor.od.com/public/kube-state-metrics:v1.5.0 [root@hdss7-200 ~]# docker push harbor.od.com/public/kube-state-metrics:v1.5.0 -
200机器,在
/data/k8s-yaml/kube-state-metrics目录下创建资源配置清单:rbac.yaml
apiVersion: v1 kind: ServiceAccount metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: kube-state-metrics namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: kube-state-metrics rules: - apiGroups: - "" resources: - configmaps - secrets - nodes - pods - services - resourcequotas - replicationcontrollers - limitranges - persistentvolumeclaims - persistentvolumes - namespaces - endpoints verbs: - list - watch - apiGroups: - policy resources: - poddisruptionbudgets verbs: - list - watch - apiGroups: - extensions resources: - daemonsets - deployments - replicasets verbs: - list - watch - apiGroups: - apps resources: - statefulsets verbs: - list - watch - apiGroups: - batch resources: - cronjobs - jobs verbs: - list - watch - apiGroups: - autoscaling resources: - horizontalpodautoscalers verbs: - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: kube-state-metrics roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-state-metrics subjects: - kind: ServiceAccount name: kube-state-metrics namespace: kube-systemdp.yaml
apiVersion: apps/v1 kind: Deployment metadata: annotations: deployment.kubernetes.io/revision: "2" labels: grafanak8sapp: "true" app: kube-state-metrics name: kube-state-metrics namespace: kube-system spec: selector: matchLabels: grafanak8sapp: "true" app: kube-state-metrics strategy: rollingUpdate: maxSurge: 25% maxUnavailable: 25% type: RollingUpdate template: metadata: labels: grafanak8sapp: "true" app: kube-state-metrics spec: containers: - name: kube-state-metrics image: harbor.od.com/public/kube-state-metrics:v1.5.0 imagePullPolicy: IfNotPresent ports: - containerPort: 8080 name: http-metrics protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /healthz port: 8080 scheme: HTTP initialDelaySeconds: 5 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 5 serviceAccountName: kube-state-metrics -
应用清单,验证kube-metrics是否正常启动:
[root@hdss7-21 ~]# for i in rbac dp ; do kubectl apply -f http://k8s-yaml.od.com/kube-state-metrics/$i.yaml;done # 查询pod的ip地址 [root@hdss7-21 ~]# curl 172.7.21.5:8080/healthz [root@hdss7-21 ~]# curl 172.7.21.5:8080/metric
交付node-exporter
node-exporter是用来监控运算节点上的宿主机的资源信息的,需要部署到所有的运算节点;
-
200机器,下载镜像:
[root@hdss7-21 ~]# docker pull prom/node-exporter:v0.15.0 v0.15.0: Pulling from prom/node-exporter [root@hdss7-21 ~]# docker images|grep node-exporter [root@hdss7-21 ~]# docker tag 12d51ffa2b22 harbor.od.com/public/node-exporter:v0.15.0 [root@hdss7-21 ~]# docker push harbor.od.com/public/node-exporter:v0.15.0 -
在/data/k8s-yaml/node-exporter目录下准备资源配置清单并在node节点应用:
ds.yaml
kind: DaemonSet apiVersion: apps/v1 metadata: name: node-exporter namespace: kube-system labels: daemon: "node-exporter" grafanak8sapp: "true" spec: selector: matchLabels: daemon: "node-exporter" grafanak8sapp: "true" template: metadata: name: node-exporter labels: daemon: "node-exporter" grafanak8sapp: "true" spec: volumes: - name: proc hostPath: path: /proc type: "" - name: sys hostPath: path: /sys type: "" containers: - name: node-exporter image: harbor.od.com/public/node-exporter:v0.15.0 imagePullPolicy: IfNotPresent args: - --path.procfs=/host_proc - --path.sysfs=/host_sys ports: - name: node-exporter hostPort: 9100 containerPort: 9100 protocol: TCP volumeMounts: - name: sys readOnly: true mountPath: /host_sys - name: proc readOnly: true mountPath: /host_proc hostNetwork: true# node节点查看9100端口是否占用,这时候应该没有9100端口 [root@hdss7-21 ~]# netstat -tlnp|grep 9100 [root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/node-exporter/ds.yaml # 再次查看端口 [root@hdss7-21 ~]# netstat -tlnp|grep 9100 tcp6 0 0 :::9100 :::* LISTEN 34179/node_exporter [root@hdss7-21 ~]# curl localhost:9100 # 查看node-exporter取出的信息 [root@hdss7-21 ~]# curl localhost:9100/metrics
交付cadvisor
cadvisor用来监控容器内部使用资源的信息,cadvisor官方dockerhub镜像
-
200机器下载镜像:
[root@hdss7-200 node-exporter]# docker pull google/cadvisor:v0.28.3 [root@hdss7-200 node-exporter]# docker images|grep cadvisor [root@hdss7-200 node-exporter]# docker tag 75f88e3ec33 harbor.od.com/public/cadvisor:v0.28.3 [root@hdss7-200 node-exporter]# docker push harbor.od.com/public/cadvisor:v0.28.3 -
在/data/k8s-yaml/cadvisor目录下创建资源配置清单,并在node节点应用:
ds.yaml
kind: DaemonSet apiVersion: apps/v1 metadata: name: cadvisor namespace: kube-system labels: app: cadvisor spec: selector: matchLabels: name: cadvisor template: metadata: labels: name: cadvisor spec: hostNetwork: true tolerations: - key: node-role.kubernetes.io/master effect: NoExecute containers: - name: cadvisor image: harbor.od.com/public/cadvisor:v0.28.3 imagePullPolicy: IfNotPresent volumeMounts: - name: rootfs mountPath: /rootfs readOnly: true - name: var-run mountPath: /var/run readOnly: true - name: docker mountPath: /var/lib/docker readOnly: true ports: - name: http containerPort: 4194 protocol: TCP readinessProbe: tcpSocket: port: 4194 initialDelaySeconds: 5 periodSeconds: 10 args: - --housekeeping_interval=10s - --port=4194 terminationGracePeriodSeconds: 30 volumes: - name: rootfs hostPath: path: / - name: var-run hostPath: path: /var/run - name: sys hostPath: path: /sys - name: docker hostPath: path: /data/docker
k8s调度调整
可人为影响k8s调度策略的三种方法:
- 污点、容忍方法:
污点:运算节点node上的污点(先在运算节点上打标签等,kubectl taint nodes node1 key1=value1:NoSchedule,污点可以有多个;
容忍度:pod能否容忍污点,参考kubernetes官网
-
nodeName:让pod运行在指定的node上;
-
nodeSelector:通过标签选择器,让pod运行在指定的一类node上。
污点配置方法:
-
给21机器打个污点,在22机器执行下面的命令:
[root@hdss7-22 ~]# kubectl taint node hdss7-21.host.com node-role.kubernetes.io/master=master:NoSchedule node/hdss7-21.host.com tainted
-
21/22机器,修改软连接:
~]# mount -o remount,rw /sys/fs/cgroup/ ~]# ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu ~]# ls -l /sys/fs/cgroup/ -
22机器应用资源清单:
[root@hdss7-22 ~]# kubectl apply -f http://k8s-yaml.od.com/cadvisor/ds.yaml daemonset.apps/cadvisor created [root@hdss7-22 ~]# kubectl get pod -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES cadvisor-xcrd7 0/1 Running 0 3s 10.4.7.22 hdss7-22.host.com <none> <none>只有22机器上有pod。
-
21机器删除污点:
[root@hdss7-22 ~]# kubectl taint node hdss7-21.host.com node-role.kubernetes.io/master- node/hdss7-21.host.com untainted

-
修改cadvisor的daemonSet:

交付blackbox-exporter
blackbox-exporter用于监控业务容器的存活性:
-
200机器下载镜像:
[root@hdss7-200 k8s-yaml]# docker pull prom/blackbox-exporter:v0.15.1 [root@hdss7-200 k8s-yaml]# docker images|grep blackbox-exporter [root@hdss7-200 k8s-yaml]# docker tag 81b70b6158be harbor.od.com/public/blackbox-exporter:v0.15.1 [root@hdss7-200 k8s-yaml]# docker push harbor.od.com/public/blackbox-exporter:v0.15.1 -
在/data/k8s-yaml/blackbox-exporter目录下准备资源配置清单,并在node节点应用:
cm.yaml
apiVersion: v1 kind: ConfigMap metadata: labels: app: blackbox-exporter name: blackbox-exporter namespace: kube-system data: blackbox.yaml: |- modules: http_2xx: prober: http timeout: 2s http: valid_http_versions: ["HTTP/1.1", "HTTP/2"] valid_status_codes: [200,301,302] method: GET preferred_ip_protocol: "ip4" tcp_connect: prober: tcp timeout: 2sdp.yaml
kind: Deployment apiVersion: apps/v1 metadata: name: blackbox-exporter namespace: kube-system labels: app: blackbox-exporter annotations: deployment.kubernetes.io/revision: 1 spec: replicas: 1 selector: matchLabels: app: blackbox-exporter template: metadata: labels: app: blackbox-exporter spec: volumes: - name: config configMap: name: blackbox-exporter defaultMode: 420 containers: - name: blackbox-exporter image: harbor.od.com/public/blackbox-exporter:v0.15.1 imagePullPolicy: IfNotPresent args: - --config.file=/etc/blackbox_exporter/blackbox.yaml - --log.level=info - --web.listen-address=:9115 ports: - name: blackbox-port containerPort: 9115 protocol: TCP resources: limits: cpu: 200m memory: 256Mi requests: cpu: 100m memory: 50Mi volumeMounts: - name: config mountPath: /etc/blackbox_exporter readinessProbe: tcpSocket: port: 9115 initialDelaySeconds: 5 timeoutSeconds: 5 periodSeconds: 10 successThreshold: 1 failureThreshold: 3svc.yaml
kind: Service apiVersion: v1 metadata: name: blackbox-exporter namespace: kube-system spec: selector: app: blackbox-exporter ports: - name: blackbox-port protocol: TCP port: 9115ingress.yaml
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: blackbox-exporter namespace: kube-system spec: rules: - host: blackbox.od.com http: paths: - path: / backend: serviceName: blackbox-exporter servicePort: blackbox-port# 批量应用 [root@hdss7-21 ~]# for i in cm dp svc ingress;do kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/$i.yaml;done -
域名解析:
2021121017 ; serial blackbox A 10.4.7.10
部署Prometheus-server
prometheus-server通过pull metrics从exporter拉取和存储监控数据,并提供一套灵活的查询语言(PromQL),prometheus-server官网docker地址
-
200机器准备镜像:
[root@hdss7-200 blackbox-exporter]# docker pull prom/prometheus:v2.14.0 [root@hdss7-200 blackbox-exporter]# docker images|grep prometheus [root@hdss7-200 blackbox-exporter]# docker tag 7317640d555e harbor.od.com/infra/prometheus:v2.14.0 [root@hdss7-200 blackbox-exporter]# docker push harbor.od.com/infra/prometheus:v2.14.0 -
在/data/k8s-yaml/prometheus目录下准备资源清单:
rbac.yaml
apiVersion: v1 kind: ServiceAccount metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: prometheus namespace: infra --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: prometheus rules: - apiGroups: - "" resources: - nodes - nodes/metrics - services - endpoints - pods verbs: - get - list - watch - apiGroups: - "" resources: - configmaps verbs: - get - nonResourceURLs: - /metrics verbs: - get --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: infradp.yaml
apiVersion: apps/v1 kind: Deployment metadata: annotations: deployment.kubernetes.io/revision: "5" labels: name: prometheus name: prometheus namespace: infra spec: progressDeadlineSeconds: 600 replicas: 1 revisionHistoryLimit: 7 selector: matchLabels: app: prometheus strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 1 type: RollingUpdate template: metadata: labels: app: prometheus spec: containers: - name: prometheus image: harbor.od.com/infra/prometheus:v2.14.0 imagePullPolicy: IfNotPresent command: - /bin/prometheus args: - --config.file=/data/etc/prometheus.yml - --storage.tsdb.path=/data/prom-db - --storage.tsdb.min-block-duration=10m - --storage.tsdb.retention=72h ports: - containerPort: 9090 protocol: TCP volumeMounts: - mountPath: /data name: data resources: requests: cpu: "1000m" memory: "1.5Gi" limits: cpu: "2000m" memory: "3Gi" imagePullSecrets: - name: harbor securityContext: runAsUser: 0 serviceAccountName: prometheus volumes: - name: data nfs: server: hdss7-200.host.com path: /data/nfs-volume/prometheussvc.yaml
apiVersion: v1 kind: Service metadata: name: prometheus namespace: infra spec: ports: - port: 9090 protocol: TCP targetPort: 9090 selector: app: prometheusingress.yaml
apiVersion: extensions/v1beta1 kind: Ingress metadata: annotations: kubernetes.io/ingress.class: traefik name: prometheus namespace: infra spec: rules: - host: prometheus.od.com http: paths: - path: / backend: serviceName: prometheus servicePort: 9090 -
配置域名解析:
2021121018 ; serial prometheus A 10.4.7.10 -
nfs配置:
[root@hdss7-200 prometheus]# mkdir /data/nfs-volume/prometheus [root@hdss7-200 prometheus]# cd !$ cd /data/nfs-volume/prometheus [root@hdss7-200 prometheus]# mkdir etc prom-db [root@hdss7-200 prometheus]# cd etc/ [root@hdss7-200 etc]# cp /opt/certs/ca.pem . [root@hdss7-200 etc]# cp -a /opt/certs/client.pem . [root@hdss7-200 etc]# cp -a /opt/certs/client-key.pem .编辑prometheus.yml配置文件:
global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'etcd' tls_config: ca_file: /data/etc/ca.pem cert_file: /data/etc/client.pem key_file: /data/etc/client-key.pem scheme: https static_configs: - targets: - '10.4.7.12:2379' - '10.4.7.21:2379' - '10.4.7.22:2379' - job_name: 'kubernetes-apiservers' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-pods' kubernetes_sd_configs: - role: pod relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name - job_name: 'kubernetes-kubelet' kubernetes_sd_configs: - role: node relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __address__ replacement: ${1}:10255 - job_name: 'kubernetes-cadvisor' kubernetes_sd_configs: - role: node relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __address__ replacement: ${1}:4194 - job_name: 'kubernetes-kube-state' kubernetes_sd_configs: - role: pod relabel_configs: - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name - source_labels: [__meta_kubernetes_pod_label_grafanak8sapp] regex: .*true.* action: keep - source_labels: ['__meta_kubernetes_pod_label_daemon', '__meta_kubernetes_pod_node_name'] regex: 'node-exporter;(.*)' action: replace target_label: nodename - job_name: 'blackbox_http_pod_probe' metrics_path: /probe kubernetes_sd_configs: - role: pod params: module: [http_2xx] relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme] action: keep regex: http - source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port, __meta_kubernetes_pod_annotation_blackbox_path] action: replace regex: ([^:]+)(?::\d+)?;(\d+);(.+) replacement: $1:$2$3 target_label: __param_target - action: replace target_label: __address__ replacement: blackbox-exporter.kube-system:9115 - source_labels: [__param_target] target_label: instance - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name - job_name: 'blackbox_tcp_pod_probe' metrics_path: /probe kubernetes_sd_configs: - role: pod params: module: [tcp_connect] relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme] action: keep regex: tcp - source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 target_label: __param_target - action: replace target_label: __address__ replacement: blackbox-exporter.kube-system:9115 - source_labels: [__param_target] target_label: instance - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name - job_name: 'traefik' kubernetes_sd_configs: - role: pod relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme] action: keep regex: traefik - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name -
应用配置清单:
# 批量应用 [root@hdss7-21 ~]# for i in rbac dp svc ingress;do kubectl apply -f http://k8s-yaml.od.com/prometheus/$i.yaml;done

Prometheus配置
监控业务容器
-
traefik配置,编辑traefik的Daemon Set,添加以下内容:
"annotations": { "prometheus_io_scheme": "traefik", "prometheus_io_path": "/metrics", "prometheus_io_port": "8080" }
然后删除traefik对应的两个pod让其重启:

-
在22机器查看traefik的pod,如果起不来就使用命令行强制删除:
~]# kubectl get pods -n kube-system ~]# kubectl delete pods traefik-ingress-g26kw -n kube-system --force --grace-period=0 -
再次访问prometheus,可以看到traefik2/2:

-
由于之前apollo已经关闭,所以重新启动一个不使用apollo的dubbo-service,到harbor里找到tag为master的dubbo-service镜像:

-
修改dubbo-service的Deployment资源配置清单文件,然后将规模scale到1启动pod:


-
监控dubbo-service活性,在dubbo-service的Deployment资源配置清单文件中,添加以下内容:
"annotations": { "blackbox_port": "20880", "blackbox_scheme": "tcp" }
-
再次刷新prometheus,已经自动发现业务:


-
同样的,把dubbo-consumer也加入监控,将dubbo-consumer的Deployment使用的镜像修改为非Apollo的版本,并且添加annotations配置:
"annotations":{ "blackbox_path": "/hello?name=health", "blackbox_port": "8080", "blackbox_scheme": "http" }
-
查看Prometheus,自动发现服务:


Grafana部署
Grafana用来代替Prometheus原生的UI界面
-
200机器准备镜像:
[root@hdss7-200 ~]# docker pull grafana/grafana:5.4.2 [root@hdss7-200 ~]# docker images|grep grafana [root@hdss7-200 ~]# docker tag 6f18ddf9e552 harbor.od.com/infra/grafana:v5.4.2 [root@hdss7-200 ~]# docker push harbor.od.com/infra/grafana:v5.4.2 -
在/data/k8s-yaml/grafana目录下创建资源配置清单:
rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-server: "true" name: grafana rules: - apiGroups: - "*" resources: - namespaces - deployments - pods verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: grafana roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: grafana subjects: - kind: User name: k8s-nodedp.yaml
# https://kubernetes.io/docs/concepts/workloads/controllers/deployment/ apiVersion: apps/v1 kind: Deployment metadata: name: grafana namespace: infra labels: app: grafana name: grafana spec: progressDeadlineSeconds: 600 revisionHistoryLimit: 7 selector: matchLabels: app: grafana replicas: 1 strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 1 type: RollingUpdate template: metadata: labels: app: grafana name: grafana spec: containers: - name: grafana image: harbor.od.com/infra/grafana:v5.4.2 imagePullPolicy: IfNotPresent ports: - containerPort: 3000 protocol: TCP volumeMounts: - name: data mountPath: /var/lib/grafana imagePullSecrets: - name: harbor securityContext: runAsUser: 0 volumes: - nfs: path: /data/nfs-volume/grafana server: hdss7-200.host.com name: data ---svc.yaml
apiVersion: v1 kind: Service metadata: name: grafana namespace: infra spec: ports: - port: 3000 protocol: TCP targetPort: 3000 selector: app: grafanaingress.yaml
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: grafana namespace: infra spec: rules: - host: grafana.od.com http: paths: - path: / backend: serviceName: grafana servicePort: 3000 -
配置域名解析:
2021121019 ; serial grafana A 10.4.7.10 -
应用配置清单:
# 批量配置 [root@hdss7-22 ~]# for i in rbac dp svc ingress;do kubectl apply -f http://k8s-yaml.od.com/grafana/$i.yaml;done -
访问grafana.od.com,账号密码都是admin,修改密码为admin123.
Grafana配置
-
修改grafana基础配置如下:

-
安装插件,进入grafana的容器,执行安装插件命令:
[root@hdss7-22 ~]# kubectl exec -it grafana-58f5f84b59-8vc7t -n infra bash # 第一个插件kubenetes App grafana-cli plugins install grafana-kubernetes-app # 第二个 Clock Pannel grafana-cli plugins install grafana-clock-panel # 第三个 Pie Chart grafana-cli plugins install grafana-piechart-panel # 第四个 D3Gauge grafana-cli plugins install briangann-gauge-panel # 第五个 Discrete grafana-cli plugins install natel-discrete-panel进入200机器的/data/nfs-volume/grafana/plugins目录,查看插件:
[root@hdss7-200 plugins]# ll 总用量 0 drwxr-xr-x 4 root root 253 3月 2 00:23 briangann-gauge-panel drwxr-xr-x 3 root root 155 3月 2 00:22 grafana-clock-panel drwxr-xr-x 4 root root 198 3月 2 00:21 grafana-kubernetes-app drwxr-xr-x 4 root root 277 3月 2 00:22 grafana-piechart-panel drwxr-xr-x 5 root root 216 3月 2 00:23 natel-discrete-panel -
删除grafana的pod让其重启,重启完成后重新访问grafana,然后添加数据源:

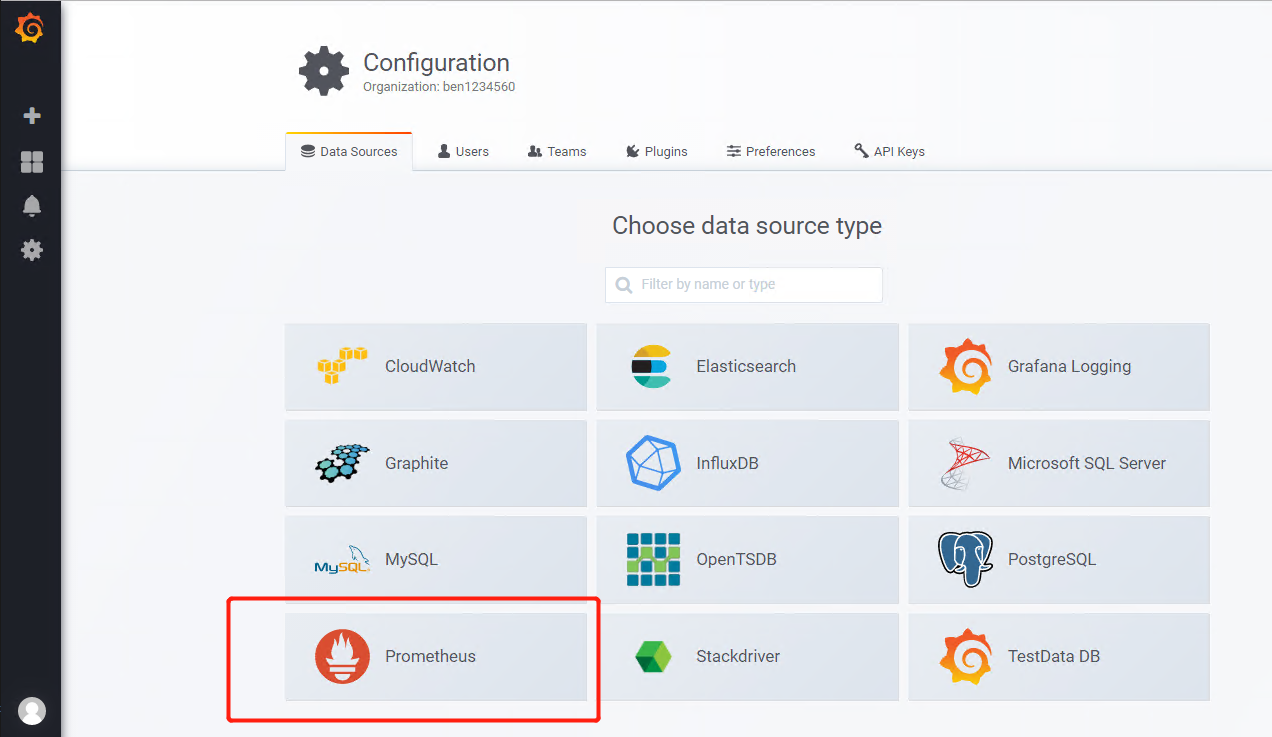
# 填入参数: URL:http://prometheus.od.com TLS Client Auth✔ With CA Cert✔
# 到200机器获取证书参数,填入grafana中 ~]# cat /opt/certs/ca.pem ~]# cat /opt/certs/client.pem ~]# cat /opt/certs/client-key.pem
-
配置plugins中的kuberntes:



# 按参数填入: Name:myk8s URL:https://10.4.7.10:7443 Access:Server TLS Client Auth✔ With CA Cert✔

-
删除grafana的dashboard:


分别点击Cluster,Container,deployment,node,然后点击配置,删除dashboard:


-
点击Home,点击Import dashboard:


-
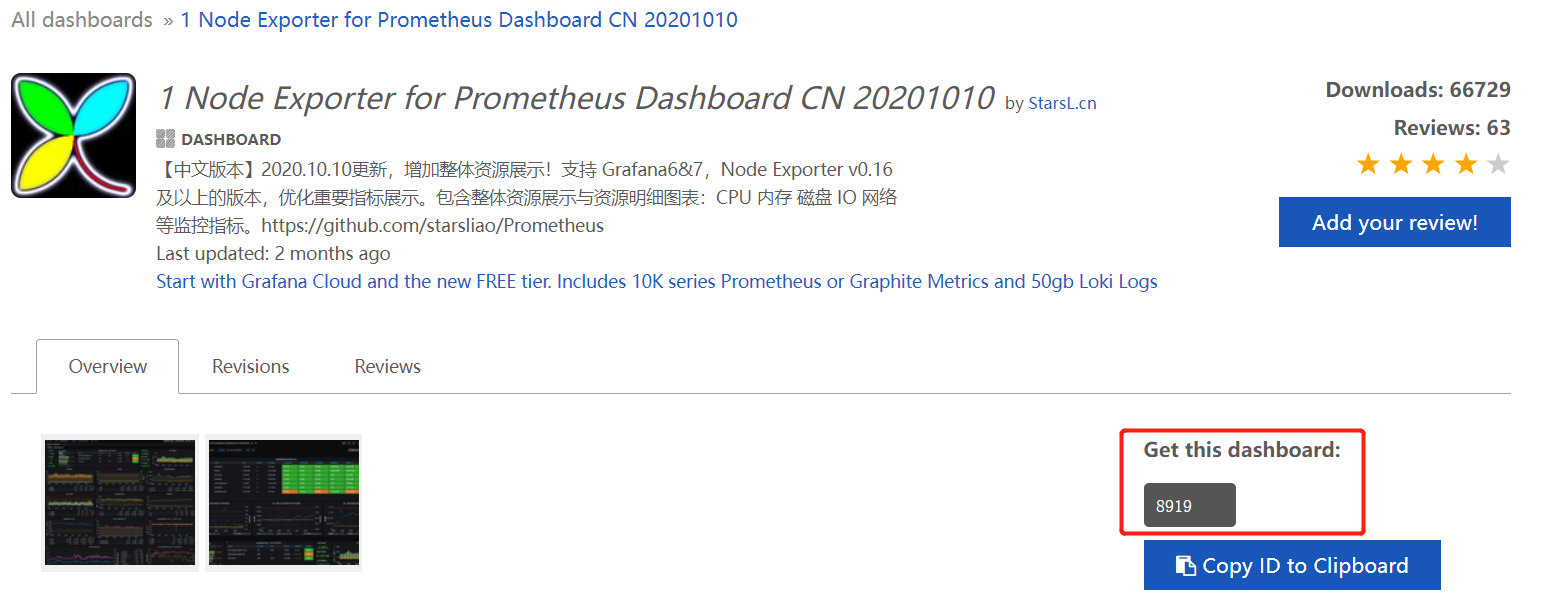
进入grafana官网,然后找到别人写好的dashboard,获取到编号,然后填入Import页面,或者直接使用k8s_PaaS/第七章——Promtheus监控k8s企业家应用.md at master · ben1234560/k8s_PaaS (github.com)提供的json文件,将所有的json文件导入进去即可:

Grafana添加dubbo数据
-
编辑dubbo-service的Deployment资源配置清单文件,添加以下内容:
"prometheus_io_scrape": "true", "prometheus_io_port": "12346", "prometheus_io_path": "/"
-
dubbo-consumer也同样添加以下内容:
"prometheus_io_scrape": "true", "prometheus_io_port": "12346", "prometheus_io_path": "/"
-
完成后刷新JMX:

alertmanager部署及配置
部署alertmanagger
从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对方的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty 等。
-
200机器准备镜像:
[root@hdss7-200 k8s-yaml]# docker pull docker.io/prom/alertmanager:v0.14.0 [root@hdss7-200 k8s-yaml]# docker images|grep alert [root@hdss7-200 k8s-yaml]# docker tag 23744b2d645c harbor.od.com/infra/alertmanager:v0.14.0 [root@hdss7-200 k8s-yaml]# docker push harbor.od.com/infra/alertmanager:v0.14.0 -
到/data/k8s-yaml/alertmanager目录下准备资源配置清单:
cm.yaml
apiVersion: v1 kind: ConfigMap metadata: name: alertmanager-config namespace: infra data: config.yml: |- global: # 在没有报警的情况下声明为已解决的时间 resolve_timeout: 5m # 配置邮件发送信息 # 根据自己的邮箱更改 smtp_smarthost: 'smtp.163.com:25' smtp_from: 'xxx@163.com' smtp_auth_username: 'xxx@163.com' smtp_auth_password: 'xxx' smtp_require_tls: false # 所有报警信息进入后的根路由,用来设置报警的分发策略 route: # 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面 group_by: ['alertname', 'cluster'] # 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。 group_wait: 30s # 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。 group_interval: 5m # 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们 repeat_interval: 5m # 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器 receiver: default receivers: - name: 'default' email_configs: - to: 'evobot@foxmail.com' send_resolved: truedp.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: alertmanager namespace: infra spec: replicas: 1 selector: matchLabels: app: alertmanager template: metadata: labels: app: alertmanager spec: containers: - name: alertmanager image: harbor.od.com/infra/alertmanager:v0.14.0 args: - "--config.file=/etc/alertmanager/config.yml" - "--storage.path=/alertmanager" ports: - name: alertmanager containerPort: 9093 volumeMounts: - name: alertmanager-cm mountPath: /etc/alertmanager volumes: - name: alertmanager-cm configMap: name: alertmanager-config imagePullSecrets: - name: harborsvc.yaml
apiVersion: v1 kind: Service metadata: name: alertmanager namespace: infra spec: selector: app: alertmanager ports: - port: 80 targetPort: 9093#应用资源配置清单 for i in cm dp svc; do kubectl apply -f http://k8s-yaml.od.com/alertmanager/$i.yaml;done
告警配置
-
在200机器的/data/nfs-volume/prometheus/etc目录下,创建rules.yml文件,内容如下:
groups: - name: hostStatsAlert rules: - alert: hostCpuUsageAlert expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85 for: 5m labels: severity: warning annotations: summary: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }}%)" - alert: hostMemUsageAlert expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85 for: 5m labels: severity: warning annotations: summary: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }}%)" - alert: OutOfInodes expr: node_filesystem_free{fstype="overlay",mountpoint ="/"} / node_filesystem_size{fstype="overlay",mountpoint ="/"} * 100 < 10 for: 5m labels: severity: warning annotations: summary: "Out of inodes (instance {{ $labels.instance }})" description: "Disk is almost running out of available inodes (< 10% left) (current value: {{ $value }})" - alert: OutOfDiskSpace expr: node_filesystem_free{fstype="overlay",mountpoint ="/rootfs"} / node_filesystem_size{fstype="overlay",mountpoint ="/rootfs"} * 100 < 10 for: 5m labels: severity: warning annotations: summary: "Out of disk space (instance {{ $labels.instance }})" description: "Disk is almost full (< 10% left) (current value: {{ $value }})" - alert: UnusualNetworkThroughputIn expr: sum by (instance) (irate(node_network_receive_bytes[2m])) / 1024 / 1024 > 100 for: 5m labels: severity: warning annotations: summary: "Unusual network throughput in (instance {{ $labels.instance }})" description: "Host network interfaces are probably receiving too much data (> 100 MB/s) (current value: {{ $value }})" - alert: UnusualNetworkThroughputOut expr: sum by (instance) (irate(node_network_transmit_bytes[2m])) / 1024 / 1024 > 100 for: 5m labels: severity: warning annotations: summary: "Unusual network throughput out (instance {{ $labels.instance }})" description: "Host network interfaces are probably sending too much data (> 100 MB/s) (current value: {{ $value }})" - alert: UnusualDiskReadRate expr: sum by (instance) (irate(node_disk_bytes_read[2m])) / 1024 / 1024 > 50 for: 5m labels: severity: warning annotations: summary: "Unusual disk read rate (instance {{ $labels.instance }})" description: "Disk is probably reading too much data (> 50 MB/s) (current value: {{ $value }})" - alert: UnusualDiskWriteRate expr: sum by (instance) (irate(node_disk_bytes_written[2m])) / 1024 / 1024 > 50 for: 5m labels: severity: warning annotations: summary: "Unusual disk write rate (instance {{ $labels.instance }})" description: "Disk is probably writing too much data (> 50 MB/s) (current value: {{ $value }})" - alert: UnusualDiskReadLatency expr: rate(node_disk_read_time_ms[1m]) / rate(node_disk_reads_completed[1m]) > 100 for: 5m labels: severity: warning annotations: summary: "Unusual disk read latency (instance {{ $labels.instance }})" description: "Disk latency is growing (read operations > 100ms) (current value: {{ $value }})" - alert: UnusualDiskWriteLatency expr: rate(node_disk_write_time_ms[1m]) / rate(node_disk_writes_completedl[1m]) > 100 for: 5m labels: severity: warning annotations: summary: "Unusual disk write latency (instance {{ $labels.instance }})" description: "Disk latency is growing (write operations > 100ms) (current value: {{ $value }})" - name: http_status rules: - alert: ProbeFailed expr: probe_success == 0 for: 1m labels: severity: error annotations: summary: "Probe failed (instance {{ $labels.instance }})" description: "Probe failed (current value: {{ $value }})" - alert: StatusCode expr: probe_http_status_code <= 199 OR probe_http_status_code >= 400 for: 1m labels: severity: error annotations: summary: "Status Code (instance {{ $labels.instance }})" description: "HTTP status code is not 200-399 (current value: {{ $value }})" - alert: SslCertificateWillExpireSoon expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30 for: 5m labels: severity: warning annotations: summary: "SSL certificate will expire soon (instance {{ $labels.instance }})" description: "SSL certificate expires in 30 days (current value: {{ $value }})" - alert: SslCertificateHasExpired expr: probe_ssl_earliest_cert_expiry - time() <= 0 for: 5m labels: severity: error annotations: summary: "SSL certificate has expired (instance {{ $labels.instance }})" description: "SSL certificate has expired already (current value: {{ $value }})" - alert: BlackboxSlowPing expr: probe_icmp_duration_seconds > 2 for: 5m labels: severity: warning annotations: summary: "Blackbox slow ping (instance {{ $labels.instance }})" description: "Blackbox ping took more than 2s (current value: {{ $value }})" - alert: BlackboxSlowRequests expr: probe_http_duration_seconds > 2 for: 5m labels: severity: warning annotations: summary: "Blackbox slow requests (instance {{ $labels.instance }})" description: "Blackbox request took more than 2s (current value: {{ $value }})" - alert: PodCpuUsagePercent expr: sum(sum(label_replace(irate(container_cpu_usage_seconds_total[1m]),"pod","$1","container_label_io_kubernetes_pod_name", "(.*)"))by(pod) / on(pod) group_right kube_pod_container_resource_limits_cpu_cores *100 )by(container,namespace,node,pod,severity) > 80 for: 5m labels: severity: warning annotations: summary: "Pod cpu usage percent has exceeded 80% (current value: {{ $value }}%)" -
编辑同目录下的prometheus.yml配置文件,在文件末尾添加以下内容:
alerting: alertmanagers: - static_configs: - targets: ["alertmanager"] rule_files: - "/data/etc/rules.yml"
-
平滑重启prometheus,到prometheus的pod所在node上,执行下面的命令:
[root@hdss7-21 ~]# ps -ef|grep prometheus # kill prometheus的进程号 [root@hdss7-21 ~]# kill -SIGHUP 75838 -
查看Prometheus的alerts:

-
告警测试,把dubbo-service的scale为0,这样consumer会进行报错告警,同时blackbox会产生failure:

Prometheus上查看alert:

-
邮箱查看告警:

完成后将dubbo-service scale回1,关闭部分pod节省资源:
[root@hdss7-21 ~]# kubectl scale deployment grafana --replicas=0 -n infra deployment.apps/grafana scaled [root@hdss7-21 ~]# kubectl scale deployment alertmanager --replicas=0 -n infra deployment.apps/alertmanager scaled [root@hdss7-21 ~]# kubectl scale deployment prometheus --replicas=0 -n infra deployment.apps/prometheus scaled
dubbo接入ELK
随着容器编排的进行,业务容器在不断被创建、摧毁、迁移、扩缩容等,面对如此海量的数据,又分布在不同的地方,就需要建立一套集中日志采集、分析的系统,这就是ELK,其可以实现以下几个功能:
- 收集——采集多种来源的日志数据(流式日志收集器)
- 传输——稳定的把日志数据传输到中央系统(消息队列)
- 存储——将日志以结构化数据的形式存储起来(搜索引擎)
- 分析——支持方便的分析、检索等,有GUI管理系统(前端)
- 告警——提供错误报告,监控机制(监控工具)

上图是ELK部署的架构,其中c1/c2是容器,filebeat收集业务容器的日志,把c和filebeat放在一个pod中,使耦合更紧;
kafka:高吞吐量的分布式发布订阅消息系统,可以处理消费者在网站中的所有动作流数据,filebeat收集数据以topic形式发布到kafka;
Topic:kafka数据写入操作的基本单元;
logstash:取kafka里的topic,然后再往Elasticsearch上传(异步过程,又取又传)
index-pattern:把数据按环境分(prod和test),并传到kibana;
kibana:展示数据。
tomcat镜像制作
-
进入200机器,tomcat官网下载tomcat,这里使用8.5.76版本:
[root@hdss7-200 etc]# cd /opt/src/ [root@hdss7-200 src]# wget https://dlcdn.apache.org/tomcat/tomcat-8/v8.5.76/bin/apache-tomcat-8.5.76.tar.gz [root@hdss7-200 src]# mkdir /data/dockerfile/tomcat [root@hdss7-200 src]# tar xvf apache-tomcat-8.5.76.tar.gz -C /data/dockerfile/tomcat/ -
注释apache-tomcat-8.5.76/conf/server.xml文件中的AJP配置:
<!-- Define an AJP 1.3 Connector on port 8009 --> <!-- <Connector protocol="AJP/1.3" address="::1" port="8009" redirectPort="8443" /> --> -
删除多余日志配置:
# 删除其中的3manager,4host-manager配置 handlers = 1catalina.org.apache.juli.AsyncFileHandler, 2localhost.org.apache.juli.AsyncFileHandler, java.util.logging.ConsoleHandler # 注释3manager,4host-manager #3manager.org.apache.juli.AsyncFileHandler.level = FINE #3manager.org.apache.juli.AsyncFileHandler.directory = ${catalina.base}/logs #3manager.org.apache.juli.AsyncFileHandler.prefix = manager. #3manager.org.apache.juli.AsyncFileHandler.encoding = UTF-8 #4host-manager.org.apache.juli.AsyncFileHandler.level = FINE #4host-manager.org.apache.juli.AsyncFileHandler.directory = ${catalina.base}/logs #4host-manager.org.apache.juli.AsyncFileHandler.prefix = host-manager. #4host-manager.org.apache.juli.AsyncFileHandler.encoding = UTF-8 # 修改日志级别 1catalina.org.apache.juli.AsyncFileHandler.level = INFO 2localhost.org.apache.juli.AsyncFileHandler.level = INFO java.util.logging.ConsoleHandler.level = INFO
-
准备dockerfile:
FROM harbor.od.com/public/jre:8u112 RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \ echo 'Asia/Shanghai' > /etc/timezone ENV CATALINA_HOME /opt/tomcat ENV LANG zh_CN.UTF-8 ADD apache-tomcat-8.5.76 /opt/tomcat ADD config.yml /opt/prom/config.yml ADD jmx_javaagent-0.3.1.jar /opt/prom/jmx_javaagent-0.3.1.jar WORKDIR /opt/tomcat ADD entrypoint.sh /entrypoint.sh CMD ["/entrypoint.sh"]config.yml
--- rules: - pattern: '_*'entrypoint.sh
#!/bin/bash M_OPTS="-Duser.timezone=Asia/Shanghai -javaagent:/opt/prom/jmx_javaagent-0.3.1.jar=$(hostname -i):${M_PORT:-"12346"}:/opt/prom/config.yml" C_OPTS=${C_OPTS} MIN_HEAP=${MIN_HEAP:-"128m"} MAX_HEAP=${MAX_HEAP:-"128m"} JAVA_OPTS=${JAVA_OPTS:-"-Xmn384m -Xss256k -Duser.timezone=GMT+08 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -Dfile.encoding=UTF8 -Dsun.jnu.encoding=UTF8"} CATALINA_OPTS="${CATALINA_OPTS}" JAVA_OPTS="${M_OPTS} ${C_OPTS} -Xms${MIN_HEAP} -Xmx${MAX_HEAP} ${JAVA_OPTS}" sed -i -e "1a\JAVA_OPTS=\"$JAVA_OPTS\"" -e "1a\CATALINA_OPTS=\"$CATALINA_OPTS\"" /opt/tomcat/bin/catalina.sh cd /opt/tomcat && /opt/tomcat/bin/catalina.sh run 2>&1 >> /opt/tomcat/logs/stdout.log# 下载javaagent: wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.3.1/jmx_prometheus_javaagent-0.3.1.jar -O jmx_javaagent-0.3.1.jar [root@hdss7-200 tomcat]# chmod +x entrypoint.sh [root@hdss7-200 tomcat]# docker build . -t harbor.od.com/base/tomcat:v8.5.76 [root@hdss7-200 tomcat]# docker push !$ -
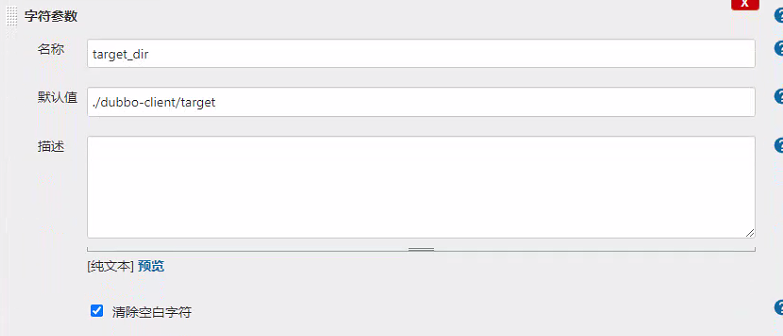
jenkins新建流水线:













pipeline { agent any stages { stage('pull') { //get project code from repo steps { sh "git clone ${params.git_repo} ${params.app_name}/${env.BUILD_NUMBER} && cd ${params.app_name}/${env.BUILD_NUMBER} && git checkout ${params.git_ver}" } } stage('build') { //exec mvn cmd steps { sh "cd ${params.app_name}/${env.BUILD_NUMBER} && /var/jenkins_home/maven-${params.maven}/bin/${params.mvn_cmd}" } } stage('unzip') { //unzip target/*.war -c target/project_dir steps { sh "cd ${params.app_name}/${env.BUILD_NUMBER} && cd ${params.target_dir} && mkdir project_dir && unzip *.war -d ./project_dir" } } stage('image') { //build image and push to registry steps { writeFile file: "${params.app_name}/${env.BUILD_NUMBER}/Dockerfile", text: """FROM harbor.od.com/${params.base_image} ADD ${params.target_dir}/project_dir /opt/tomcat/webapps/${params.root_url}""" sh "cd ${params.app_name}/${env.BUILD_NUMBER} && docker build -t harbor.od.com/${params.image_name}:${params.git_ver}_${params.add_tag} . && docker push harbor.od.com/${params.image_name}:${params.git_ver}_${params.add_tag}" } } } } -
点击构建,填入以下参数:
app_name: dubbo-demo-web image_name: app/dubbo-demo-web git_repo: -b client git@gitee.com:evobot/dubbo-demo-web.git git_ver: tomcat add_tag: 220303-1730 mvn_dir: ./ target_dir: ./dubbo-client/target mvn_cmd: mvn clean package -Dmaven.test.skip=true base_image: base/tomcat:v8.5.76 maven: 3.6.1-8u242 root_url: ROOT # 点击Build进行构建,等待构建完成 -
build成功后,将apollo scale到1,然后修改test命名空间dubbo-demo-consumer的deployment中的image版本号以及删除20880端口号,然后更新pod:


-
访问demo-test.od.com/hello?name=tomcat页面:

-
进入consumer的pod命令行,查看日志,下面显示的就是需要收集的日志:

部署elasticsearch
这里只部署一个elasticsearch节点。
-
官网下载包,选择MACOS/LINUX右键复制链接下载到12机器:
[root@hdss7-12 src]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.8.6.tar.gz [root@hdss7-12 src]# tar xvf elasticsearch-6.8.6.tar.gz -C /opt/ [root@hdss7-12 src]# ln -s /opt/elasticsearch-6.8.6/ /opt/elasticsearch [root@hdss7-12 src]# cd /opt/elasticsearch [root@hdss7-12 elasticsearch]# mkdir -p /data/elasticsearch/{data,logs} -
配置elasticsearch,编辑config/elasticsearch.yml,修改以下内容:
cluster.name: es.od.com node.name: hdss7-12.host.com path.data: /data/elasticsearch/data path.logs: /data/elasticsearch/logs bootstrap.memory_lock: true network.host: 10.4.7.12 http.port: 9200 -
编辑config/jvm.options,修改以下内容:
-Xms512m -Xmx512m -
创建用户及调整系统参数:
[root@hdss7-21 elasticsearch]# useradd -s /bin/bash -M es [root@hdss7-21 elasticsearch]# chown -R es.es /opt/elasticsearch-6.8.6/ [root@hdss7-21 elasticsearch]# chown -R es.es /opt/elasticsearch [root@hdss7-21 elasticsearch]# chown -R es.es /data/elasticsearch/ # vi /etc/security/limits.d/es.conf写入以下内容 es hard nofile 65536 es soft fsize unlimited es hard memlock unlimited es soft memlock unlimited # 调整内核参数 [root@hdss7-21 elasticsearch]# sysctl -w vm.max_map_count=262144 [root@hdss7-21 elasticsearch]# echo 'vm.max_map_count=262144' >> /etc/sysctl.conf [root@hdss7-21 elasticsearch]# sysctl -p -
启动es并调整日志模板:
[root@hdss7-21 elasticsearch]# su -c "/opt/elasticsearch/bin/elasticsearch -d" es [root@hdss7-21 elasticsearch]# netstat -tlunp|grep 9200 # 调整日志模板 [root@hdss7-21 elasticsearch]# curl -H "Content-Type:application/json" -XPUT http://10.4.7.12:9200/_template/k8s -d '{ > "template": "k8s*", > "index_patterns": ["k8s*"], > "settings": { > "number_of_shards":5, > "number_of_replicas": 0 > } > }'
部署kafka和kafka-manager
部署kafka
-
在11机器下载kafka安装包:
cd /opt/src/ src]# wget https://archive.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz src]# tar xfv kafka_2.12-2.2.0.tgz -C /opt/ src]# ln -s /opt/kafka_2.12-2.2.0/ /opt/kafka src]# cd /opt/kafka kafka]# mkdir -pv /data/kafka/logs -
配置kafka:
# vi config/server.properties # 修改以下配置,其中zk不变 kafka]# vi config/server.properties log.dirs=/data/kafka/logs zookeeper.connect=localhost:2181 log.flush.interval.messages=10000 log.flush.interval.ms=1000\ # 下面两行则新增到尾部 delete.topic.enable=true host.name=hdss7-11.host.com -
启动kafka:
[root@hdss7-11 kafka]# bin/kafka-server-start.sh -daemon config/server.properties # 获取kafka的进程PID [root@hdss7-11 kafka]# ps aux|grep kafka # 查看进程ID监听的端口 [root@hdss7-11 kafka]# netstat -tlnp |grep 125525
部署kafka-manager
-
200机器,制作docker:
[root@hdss7-200 src]# docker pull hlebalbau/kafka-manager [root@hdss7-200 src]# docker images|grep kafka [root@hdss7-200 src]# docker tag 2743fc8f2a3e harbor.od.com/infra/kafka-manager:latest
[root@hdss7-200 src]# docker push !$
2. 在/data/k8s-yaml/kafka-manager目录下创建资源配置清单,并在node节点应用:
**dp.yaml**
```yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: kafka-manager
namespace: infra
labels:
name: kafka-manager
spec:
template:
metadata:
labels:
app: kafka-manager
spec:
containers:
- name: kafka-manager
image: harbor.od.com/infra/kafka-manager:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9000
protocol: TCP
env:
- name: ZK_HOSTS
value: zk1.od.com:2181
- name: APPLICATION_SECRET
value: letmein
imagePullSecrets:
- name: harbor
terminationGracePeriodSeconds: 30
securityContext:
runAsUser: 0
replicas: 1
selector:
matchLabels:
app: kafka-manager
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
revisionHistoryLimit: 7
progressDeadlineSeconds: 600
svc.yaml
kind: Service
apiVersion: v1
metadata:
name: kafka-manager
namespace: infra
spec:
ports:
- protocol: TCP
port: 9000
targetPort: 9000
selector:
app: kafka-manager
ingress.yaml
kind: Ingress
apiVersion: extensions/v1beta1
metadata:
name: kafka-manager
namespace: infra
spec:
rules:
- host: km.od.com
http:
paths:
- path: /
backend:
serviceName: kafka-manager
servicePort: 9000
# 批量应用
[root@hdss7-22 ~]# for i in dp svc ingress;do kubectl apply -f http://k8s-yaml.od.com/kafka-manager/$i.yaml;done
-
域名配置
2021121020 ; serial km A 10.4.7.10 -
访问km.od.com,添加cluster:

如果出现
Yikes! KeeperErrorCode = Unimplemented for /kafka-manager/mutex Try again.的报错,就进入zk1的zookeeper,手动创建节点:[root@hdss7-11 zookeeper]# ./bin/zkCli.sh [zk: localhost:2181(CONNECTED) 1] ls /kafka-manager [configs, deleteClusters, clusters] [zk: localhost:2181(CONNECTED) 2] create /kafka-manager/mutex "" Created /kafka-manager/mutex [zk: localhost:2181(CONNECTED) 3] create /kafka-manager/mutex/locks "" Created /kafka-manager/mutex/locks [zk: localhost:2181(CONNECTED) 4] create /kafka-manager/mutex/leases "" -
查看cluster:

dubbo接入filebeat
-
到Filebeat官网下载Linux 64-BIT的sha指纹:

复制选中部分:

-
将test命名空间的所有pod启动,然后在200机器准备镜像:

vi /data/dockerfile/filebeat/Dockerfile
FROM debian:jessie ENV FILEBEAT_VERSION=7.6.1 \ FILEBEAT_SHA1=887edb2ab255084ef96dbc4c7c047bfa92dad16f263e23c0fcc80120ea5aca90a3a7a44d4783ba37b135dac76618971272a591ab4a24997d8ad40c7bc23ffabf RUN set -x && \ apt-get update && \ wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-${FILEBEAT_VERSION}-linux-x86_64.tar.gz -O /opt/filebeat.tar.gz && \ cd /opt && \ echo "${FILEBEAT_SHA1} filebeat.tar.gz" | sha512sum -c - && \ tar xzvf filebeat.tar.gz && \ cd filebeat-* && \ cp filebeat /bin && \ cd /opt && \ rm -rf filebeat* && \ apt-get purge -y wget && \ apt-get autoremove -y && \ apt-get clean && rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* COPY docker-entrypoint.sh / ENTRYPOINT ["/docker-entrypoint.sh"]docker-entrypoint.sh
#!/bin/bash ENV=${ENV:-"test"} PROJ_NAME=${PROJ_NAME:-"no-define"} MULTILINE=${MULTILINE:-"^\d{2}"} cat > /etc/filebeat.yaml << EOF filebeat.inputs: - type: log fields_under_root: true fields: topic: logm-${PROJ_NAME} paths: - /logm/*.log - /logm/*/*.log - /logm/*/*/*.log - /logm/*/*/*/*.log - /logm/*/*/*/*/*.log scan_frequency: 120s max_bytes: 10485760 multiline.pattern: '$MULTILINE' multiline.negate: true multiline.match: after multiline.max_lines: 100 - type: log fields_under_root: true fields: topic: logu-${PROJ_NAME} paths: - /logu/*.log - /logu/*/*.log - /logu/*/*/*.log - /logu/*/*/*/*.log - /logu/*/*/*/*/*.log - /logu/*/*/*/*/*/*.log output.kafka: hosts: ["10.4.7.11:9092"] topic: k8s-fb-$ENV-%{[topic]} version: 2.0.0 required_acks: 0 max_message_bytes: 10485760 EOF set -xe # If user don't provide any command # Run filebeat if [[ "$1" == "" ]]; then exec filebeat -c /etc/filebeat.yaml else # Else allow the user to run arbitrarily commands like bash exec "$@" fi[root@hdss7-200 filebeat]# chmod +x entrypoint.sh [root@hdss7-200 filebeat]# docker build . -t harbor.od.com/infra/filebeat:v7.6.1 [root@hdss7-200 filebeat]# docker push !$ -
清空/data/k8s-yaml/test/dubbo-demo-consumer目录下的资源配置清单,使用下面的配置:
dp.yaml
kind: Deployment apiVersion: apps/v1 metadata: name: dubbo-demo-consumer namespace: test labels: name: dubbo-demo-consumer spec: replicas: 1 selector: matchLabels: name: dubbo-demo-consumer template: metadata: labels: app: dubbo-demo-consumer name: dubbo-demo-consumer spec: containers: - name: dubbo-demo-consumer image: harbor.od.com/app/dubbo-demo-web:tomcat_220303_1730 imagePullPolicy: IfNotPresent ports: - containerPort: 8080 protocol: TCP env: - name: C_OPTS value: -Denv=fat -Dapollo.meta=http://apollo-configservice:8080 volumeMounts: - mountPath: /opt/tomcat/logs name: logm - name: filebeat image: harbor.od.com/infra/filebeat:v7.6.1 imagePullPolicy: IfNotPresent env: - name: ENV value: test - name: PROJ_NAME value: dubbo-demo-web volumeMounts: - mountPath: /logm name: logm volumes: - emptyDir: {} name: logm imagePullSecrets: - name: harbor restartPolicy: Always terminationGracePeriodSeconds: 30 securityContext: runAsUser: 0 schedulerName: default-scheduler strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 maxSurge: 1 revisionHistoryLimit: 7 progressDeadlineSeconds: 600 -
应用资源配置清单,查看filebeat:
[root@hdss7-22 ~]# kubectl apply -f http://k8s-yaml.od.com/test/dubbo-demo-consumer/dp.yaml [root@hdss7-21 ~]# docker ps -a |grep consumer [root@hdss7-21 ~]# docker exec -it 9eb3ee5ed02c bash root@dubbo-demo-consumer-669f6845b7-xrvhr:/# cd /logm/ root@dubbo-demo-consumer-669f6845b7-xrvhr:/logm# ls catalina.2022-03-04.log localhost.2022-03-04.log localhost_access_log.2022-03-04.txt stdout.log # 每刷新一次demo页面,这个日志都会更新 root@dubbo-demo-consumer-669f6845b7-xrvhr:/logm# tail -f stdout.log
部署logstash
-
准备镜像,logstash的版本需要和es一致:
[root@hdss7-200 src]# docker pull logstash:6.8.6 [root@hdss7-200 src]# docker images|grep logstash [root@hdss7-200 src]# docker tag d0a2dac51fcb harbor.od.com/infra/logstash:v6.8.6 [root@hdss7-200 src]# docker push harbor.od.com/infra/logstash:v6.8.6 -
创建配置文件
[root@hdss7-200 src]# mkdir /etc/logstash [root@hdss7-200 src]# vi /etc/logstash/logstash-test.conf [root@hdss7-200 src]# vi /etc/logstash/logstash-prod.conflogstash-test.conf
input { kafka { bootstrap_servers => "10.4.7.11:9092" client_id => "10.4.7.200" consumer_threads => 4 group_id => "k8s_test" topics_pattern => "k8s-fb-test-.*" } } filter { json { source => "message" } } output { elasticsearch { hosts => ["10.4.7.12:9200"] index => "k8s-test-%{+YYYY.MM.DD}" } }logstash-prod.conf
input { kafka { bootstrap_servers => "10.4.7.11:9092" client_id => "10.4.7.200" consumer_threads => 4 group_id => "k8s_prod" topics_pattern => "k8s-fb-prod-.*" } } filter { json { source => "message" } } output { elasticsearch { hosts => ["10.4.7.12:9200"] index => "k8s-prod-%{+YYYY.MM.DD}" } } -
启动logstash:
[root@hdss7-200 src]# docker run -d --name logstash-test -v /etc/logstash:/etc/logstash harbor.od.com/infra/logstash:v6.8.6 -f /etc/logstash/logstash-test.conf [root@hdss7-200 src]# docker ps -a |grep logstash -
刷新demo页面,让kafka里更新日志,然后查看es索引:

[root@hdss7-200 src]# curl http://10.4.7.12:9200/_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open k8s-test-2022.03.63 -KUK0rBmR3SUlgY7QzklTw 5 0 2 0 24.8kb 24.8kb [root@hdss7-200 src]#
交付kibana
-
镜像准备:
[root@hdss7-200 src]# docker pull kibana:6.8.6 [root@hdss7-200 src]# docker images|grep kibana [root@hdss7-200 src]# docker tag adfab5632ef4 harbor.od.com/infra/kibana:v6.8.6 [root@hdss7-200 src]# docker push harbor.od.com/infra/kibana:v6.8.6 -
200机器在/data/k8s-yaml/kibana目录下准备资源配置清单文件:
dp.yaml
kind: Deployment apiVersion: apps/v1 metadata: name: kibana namespace: infra labels: name: kibana spec: replicas: 1 selector: matchLabels: name: kibana template: metadata: labels: app: kibana name: kibana spec: containers: - name: kibana image: harbor.od.com/infra/kibana:v6.8.6 imagePullPolicy: IfNotPresent ports: - containerPort: 5601 protocol: TCP env: - name: ELASTICSEARCH_URL value: http://10.4.7.12:9200 imagePullSecrets: - name: harbor securityContext: runAsUser: 0 strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 maxSurge: 1 revisionHistoryLimit: 7 progressDeadlineSeconds: 600svc.yaml
kind: Service apiVersion: v1 metadata: name: kibana namespace: infra spec: ports: - protocol: TCP port: 5601 targetPort: 5601 selector: app: kibanaingress.yaml
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: kinbana namespace: infra spec: rules: - host: kibana.od.com http: paths: - path: / backend: serviceName: kibana servicePort: 5601 --- -
配置域名解析,应用资源配置清单:
2021121021 ; serial kibana A 10.4.7.10# 22机器批量应用 [root@hdss7-22 ~]# for i in dp svc ingress;do kubectl apply -f http://k8s-yaml.od.com/kibana/$i.yaml;done -
访问kibana.od.com




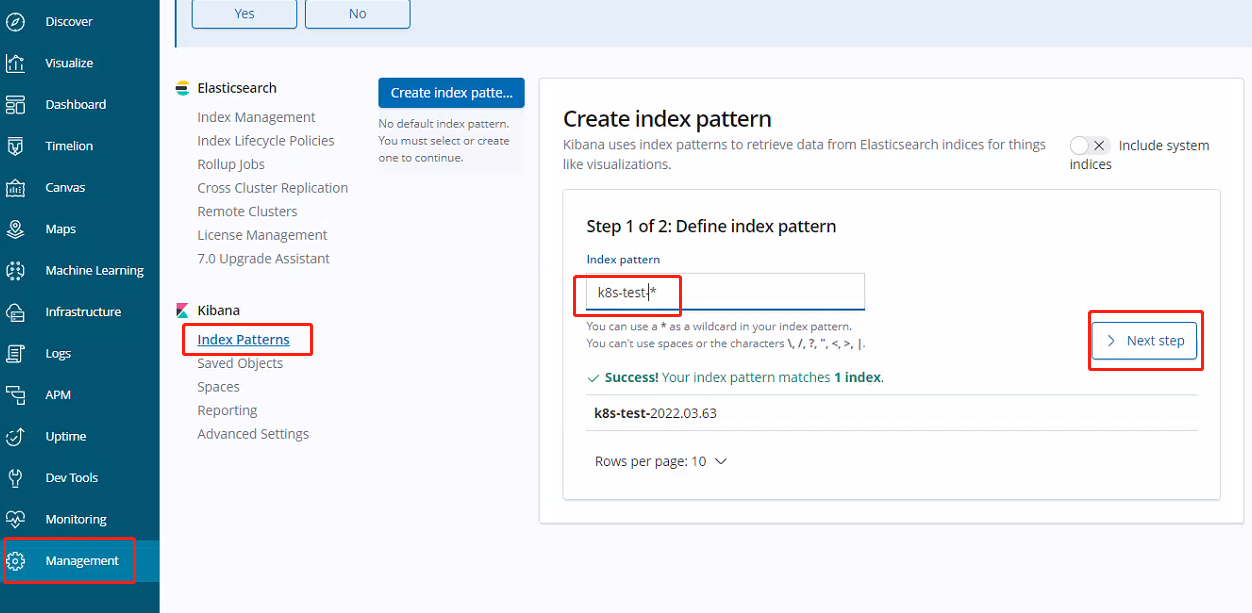


然后就可以看到日志:

-
接着把prod命名空间里的configservice和admin启动起来:

-
200机器,复制test/dubbo-demo-consumer下的dp.yaml,放到prod同目录下,并修改其中的namespace为pro:
[root@hdss7-200 prod]# cd dubbo-demo-consumer/ [root@hdss7-200 dubbo-demo-consumer]# ls dp.yaml ingress.yaml svc.yaml [root@hdss7-200 dubbo-demo-consumer]# cp ../../test/dubbo-demo-consumer/dp.yaml . cp:是否覆盖"./dp.yaml"? y [root@hdss7-200 dubbo-demo-consumer]# sed -i 's/fat/pro/g' dp.yaml [root@hdss7-200 dubbo-demo-consumer]# sed -i 's/test/prod/g' dp.yaml
Kibana生产实践
日志采集
-
确认config-prod.od.com的Eureka有config和admin服务:

-
确认apollo里FAT和PRO环境都存在

-
确认完毕后,将prod命名空间的dubbo-demo-service的pod启动:

-
然后应用新的consumer deploymet:
[root@hdss7-22 ~]# kubectl apply -f http://k8s-yaml.od.com/prod/dubbo-demo-consumer/dp.yaml deployment.apps/dubbo-demo-consumer configured -
200机器,创建prod环境的logstash:
[root@hdss7-200 dubbo-demo-consumer]# docker run -d --name logstash-prod -v /etc/logstash:/etc/logstash harbor.od.com/infra/logstash:v6.8.6 -f /etc/logstash/logstash-prod.conf [root@hdss7-200 dubbo-demo-consumer]# docker ps|grep logstash # curl es,这时候只有test [root@hdss7-200 dubbo-demo-consumer]# curl http://10.4.7.12:9200/_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .monitoring-kibana-6-2022.03.04 Bv6cXIk4RqeqyJbJCeCL0w 1 0 2433 0 613.2kb 613.2kb green open .kibana_1 yyHJ8l5qT3uC2Hz4lAeUPA 1 0 5 0 25.2kb 25.2kb green open .kibana_task_manager Xalxgst9SjOE38Z-2HgQIA 1 0 2 0 12.5kb 12.5kb green open k8s-test-2022.03.63 -KUK0rBmR3SUlgY7QzklTw 5 0 153 0 465.8kb 465.8kb green open .monitoring-es-6-2022.03.04 BxxwSy44SkCy6Q69926TLg 1 0 22021 36 9.2mb 9.2mb -
浏览器访问demo-prod.od.com,然后查看filebeat的日志:


[root@hdss7-21 ~]# docker ps -a |grep consumer 1c3fc912fbe4 b5194046a19c "/docker-entrypoint.…" 14 minutes ago Up 14 minutes k8s_filebeat_dubbo-demo-consumer-6b4b988fbb-fp2lx_prod_0c2c12cd-11af-4f90-a8bc-4fc36d038fac_0 a46c7fdf2bd6 80ef6604725e "/entrypoint.sh" 15 minutes ago Up 14 minutes k8s_dubbo-demo-consumer_dubbo-demo-consumer-6b4b988fbb-fp2lx_prod_0c2c12cd-11af-4f90-a8bc-4fc36d038fac_0 8158e0aeaa28 harbor.od.com/public/pause:latest "/pause" 15 minutes ago Up 14 minutes k8s_POD_dubbo-demo-consumer-6b4b988fbb-fp2lx_prod_0c2c12cd-11af-4f90-a8bc-4fc36d038fac_0 [root@hdss7-21 ~]# docker exec -it 1c3fc912fbe4 bash
到km.od.com查看

-
200机器,查询es:

-
然后去kibana进行配置:


kibana使用
时间选择


使用最多的是today:

环境选择器

关键字选择器
选择message,log.file.path,hostname几项

尝试制造错误,将test环境的service scale为0

然后刷新demo-test.od.com,让其报错:

在kibana中搜索exception关键字:


这样整个consumer的日志采集就已经完成了,完成后恢复service的pod。