Linux正则表达式——grep命令

正则表达式又称为规则表达式,是用事先定义好的一些特定的字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑;掌握好正则对于编写shell脚本也会有很大的帮助。
grep命令的用法
grep命令主要用来过滤指定的关键词的,最简单的用法是grep [keyword] [filename],在Centos7中使用grep命令,会自动高亮显示过滤的关键词。
grep命令的选项
-
grep -c选项,用来过滤行数,即存在过滤的关键词的行有多少:[root@evobot ~]# grep -c 'nologin' passwd 21 -
grep -n选项,用来显示行号:[root@evobot ~]# grep -n 'bash' passwd 1:root:x:0:0:root:/root:/bin/bash 26:centos:x:1000:1000:Cloud User:/home/centos:/bin/bash 27:lux:x:1001:1001::/home/lux:/bin/bash 29:evobot:x:1002:1002::/home/evobot:/bin/bash -
grep -i选项,表示不区分大小写过滤关键字:[root@evobot ~]# grep -ni 'bash' passwd 1:root:x:0:0:root:/root:/bin/bash 26:centos:x:1000:1000:Cloud User:/home/centos:/bin/BASH # 大写被过滤出来 27:lux:x:1001:1001::/home/lux:/bin/bash 29:evobot:x:1002:1002::/home/evobot:/bin/bash [root@evobot ~]# grep -n 'bash' passwd 1:root:x:0:0:root:/root:/bin/bash 27:lux:x:1001:1001::/home/lux:/bin/bash 29:evobot:x:1002:1002::/home/evobot:/bin/bash -
grep -v选项,表示取反过滤,即过滤出不包括关键字的行:[root@evobot ~]# grep -nv 'nologin' passwd 1:root:x:0:0:root:/root:/bin/bash 6:sync:x:5:0:sync:/sbin:/bin/sync 7:shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 8:halt:x:7:0:halt:/sbin:/sbin/halt 25:syslog:x:996:994::/home/syslog:/bin/false 26:centos:x:1000:1000:Cloud User:/home/centos:/bin/BASH 27:lux:x:1001:1001::/home/lux:/bin/bash 29:evobot:x:1002:1002::/home/evobot:/bin/bash -
grep -r [keyword] [dir]选项,表示遍历所有子目录内文件的内容,并过滤出关键字:[root@evobot grepprac]# ls 1.sh 2.sh [root@evobot grepprac]# grep -rn 'bash' ./ ./1.sh:1:#!/bin/bash ./2.sh:1:#!/bin/bash -
grep -[A/B/C]n三个选项:An选项表示过滤出符合要求的行及其下面n行;Bn选项表示过滤出复合要求的行及其上面n行;Cn选项表示过滤出复合要求的行及其上下各n行。
[root@evobot ~]# grep -nA2 'root' passwd 1:root:x:0:0:root:/root:/bin/bash 2-bin:x:1:1:bin:/bin:/sbin/nologin 3-daemon:x:2:2:daemon:/sbin:/sbin/nologin -- 10:operator:x:11:0:operator:/root:/sbin/nologin 11-games:x:12:100:games:/usr/games:/sbin/nologin 12-ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin [root@evobot ~]# grep -nB2 'root' passwd 1:root:x:0:0:root:/root:/bin/bash # 这里由于是第一行,所以无法列出上面两行 -- 8-halt:x:7:0:halt:/sbin:/sbin/halt 9-mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 10:operator:x:11:0:operator:/root:/sbin/nologin [root@evobot ~]# grep -nC1 'false' passwd 24-tcpdump:x:72:72::/:/sbin/nologin 25:syslog:x:996:994::/home/syslog:/bin/false 26-centos:x:1000:1000:Cloud User:/home/centos:/bin/BASH -
grep过滤结果中包括或排除指定的文件,使用--include包括,--exclude排除,如只在目录中的.py和.html中过滤内容:[root@evobot ~]# grep -r --include '*.py' 'yield' '.' ./Scripts/generate_company_test_datas.py: yield User( ./Scripts/generate_company_test_datas.py: yield Resume( ./Scripts/generate_company_test_datas.py: yield Seeker( ./Scripts/generate_company_test_datas.py: yield Delivery( ./Scripts/generate_company_test_datas.py: yield User( ./Scripts/generate_company_test_datas.py: yield photo['manager_photo'] ./Scripts/generate_company_test_datas.py: yield Company( ./Scripts/generate_company_test_datas.py: yield Job([root@evobot ~]# grep -r --exclude '*.py' 'endpoint' '.' ./jobplus/templates/macros.html: <li><a href="{{ url_for(endpoint, page=page, company_id=company_id) }}">{{ page }}</a></li> ./jobplus/templates/macros.html: <li{% if not pagination.has_next %} class="disabled"{% endif %}><a href="{{url_for(endpoint, page=pagination.next_num, company_id=company_id) if pagination.has_next else '#'}}">»</a></li>
正则表达式
基础正则表达式
| 元字符 | 作用 |
|---|---|
* | 前一个字符匹配0次或任意多次,匹配0次前一个字符则表示匹配任意字符,包括空白行 |
. | 匹配除了换行符以外任意一个字符,“.*”匹配所有内容 |
^ | 用于指定匹配字符串的头部,也称行首定位符;匹配行首。例如:hello会匹配以hello开头的行,grep -n “$” test.txt匹配空白行并显示行号 |
$ | 用于指定匹配字符串的尾部,也称行尾定位符;匹配行尾。例如:hello$会匹配以hello结尾的行 |
[] | 匹配中括号中指定的任意一个字符,只匹配一个字符,要匹配[则要转义\[ |
[^] | 匹配除中括号的字符以外的任意一个字符 |
\ | 转义符用于取消特殊符号的含义,匹配包含以.结尾的行grep “\.$” test.txt |
\{n\} | 表示其前面的字符恰好出现n次。例如:[0-9]{4}匹配4位数字,但注意添加两边的定界符,以精确匹配 |
\{n,\} | 表示其前面的字符出现不小于n次。例如:[0-9]{2,}匹配2位以上的数字 |
\{n,m\} | 表示其前面的字符至少出现n次,最多出现m次。例如:[a-z]{6,8}匹配6到8位的小写字母 |
扩展正则表达式
| 元字符 | 作用 |
|---|---|
| | 管道符,表示“或”,即匹配其中任何一个,”book|desk”将匹配”book”或”desk” |
() | 小括号,可以将正则字符和元字符或表达式进行组合,”(book|desk)s”将匹配”books”或”desks” |
? | 问号,匹配0个或1个前导表达式,如”a?”匹配其他字符串或a |
\< | 反斜杠+小于号,词首定位符, “< abc”表示所有包含以”abc”开头的单词的行 |
\> | 反斜杠+大于号,词尾定位符, “>abc”表示所有包含以”abc”结尾的单词的行 |
- | 减号,用于指明字符范围, “[a-c]”将匹配包含a、b和c中任意一个字符的字符串 |
+ | 加号,匹配一个或多个前导表达式,相当于 expr{1,} |
- 在
grep中使用扩展正则表达式需要使用grep -E [pattern] [filename],相当于egrep;
grep/egrep示例
-
egrep相当于grep的增强版,能够是现实grep的所有功能; -
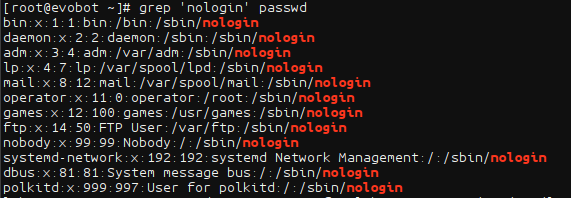
grep/egrep可以在过滤时使用正则表达式表示关键字,比如过滤出所有包含数字的行:grep [0-9] [filename]:[root@evobot ~]# grep [0-9] passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync polkitd:x:999:997:User for polkitd:/:/sbin/nologin
示例
-
过滤不包含数字的行:
[root@evobot ~]# grep -nv '[0-9]' 2.sh 1:#!/bin/bash 2: 5:A=C 6:export A -
过滤指定关键字开头的行:
[root@evobot ~]# grep -n '^#' 2.sh
1:#!/bin/bash
- 过滤
#开头的注释行并去除空行:
[root@evobot ~]# grep -vn '^#' inittab
9:assdfg
13:24vubnklm
14:afggwege
15:
[root@evobot ~]# grep -v '^#' inittab |grep -vn '^$'
1:assdfg
2:24vubnklm
3:afggwege
- 过滤非数字的行和非数字开头的行:
非数字的行,包含数字的行中,除数字外都被匹配
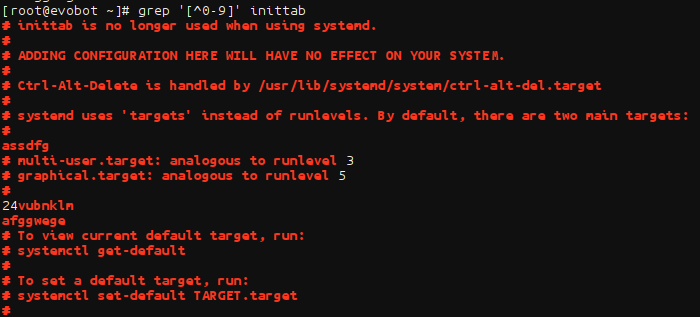
过滤非数字开头的行
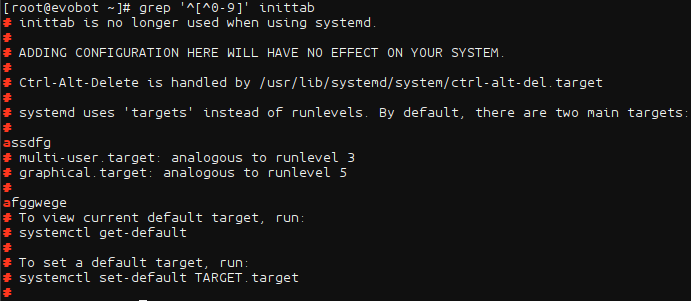
- 过滤包含任意一个字符的关键字:
[root@evobot ~]# grep 'r.o' passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@evobot ~]# grep 'ba.' passwd
root:x:0:0:root:/root:/bin/bash
lux:x:1001:1001::/home/lux:/bin/bash
evobot:x:1002:1002::/home/evobot:/bin/bash
- 过滤前一个字符0次或多次:
[root@evobot ~]# grep 'ro*t' passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
abrt:x:173:173::/etc/abrt:/sbin/nologin
[root@evobot ~]# grep 'c.*' passwd
sync:x:5:0:sync:/sbin:/bin/sync
libstoragemgmt:x:998:996:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin
abrt:x:173:173::/etc/abrt:/sbin/nologin
rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
chrony:x:997:995::/var/lib/chrony:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
centos:x:1000:1000:Cloud User:/home/centos:/bin/BASH
- 指定范围过滤:
[root@evobot ~]# grep 'o\{2\}' passwd
root:x:0:0:root:/root:/bin/bash
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
[root@evobot ~]# grep 'o\{2,3\}' passwd
root:x:0:0:root:/root:/bin/bash
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spoool/mail:/sbin/nologin
operator:x:11:0:operator:/rooooot:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/noooologin
rpc:x:32:32:Rpcbind Daemoon:/var/lib/rpcbind:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
-
上面的过滤中需要对
{}进行脱义,如果不想使用脱义符,可以使用grep -E选项,或者直接使用egrep进行过滤:[root@evobot ~]# egrep 'root|lux' passwd root:x:0:0:root:/root:/bin/bash lux:x:1001:1001::/home/lux:/bin/bash