logstash排障及kibana配置
- logstash服务启动错误排查
- kibana查看日志
logstash服务启动错误排查
-
在上一篇文章的操作中,是将syslog日志输出到了屏幕打印,方便测试和排查,而在正常运行中,需要将日志输出到elasticsearch中去,所以需要对配置文件进行更改;
-
编辑
/etc/logstash/conf.d/syslog.conf,更改如下:input { syslog { type => "system-syslog" port => 10514 } } output { elasticsearch { hosts => ["192.168.139.128:9200"] index => "system-syslog-%{+YYYY.MM}" } }将之前的屏幕输出stdout改为elasticsearch,并且指定es的ip地址,由于es是分布式架构,所以这里除了指定主节点的ip之外,指定其他数据节点的ip同样可以,index是定义索引。
-
保存配置后,再次运行命令检查配置是否正确:
[root@centos2 bin]# ./logstash --path.settings /etc/logstash/ -f /etc/logstash/conf.d/syslog.conf --config.test_and_exit Sending Logstash's logs to /var/log/logstash which is now configured via log4j2.properties Configuration OK -
执行
systemctl start logstash启动logstash,使用root用户启动logstash可能会出现启动失败的情况,在/var/log/message里能够看到:Apr 21 23:19:58 centos2 logstash: Caused by: java.lang.IllegalStateException: ManagerFactory [org.apache.logging.log4j.core.appender.rolling.RollingFileManager$RollingFileManagerFactory@66ac09d3] unable to create manager for [/var/log/logstash/logstash-plain.log] with data [org.apache.logging.log4j.core.appender.rolling.RollingFileManager$FactoryData@c85c20c[pattern=/var/log/logstash/logstash-plain-%d{yyyy-MM-dd}.log, append=true, bufferedIO=true, bufferSize=8192, policy=CompositeTriggeringPolicy(policies=[TimeBasedTriggeringPolicy(nextRolloverMillis=0, interval=1, modulate=true)]), strategy=DefaultRolloverStrategy(min=1, max=7), advertiseURI=null, layout=[%d{ISO8601}][%-5p][%-25c] %-.10000m%n]] Apr 21 23:19:58 centos2 logstash: at org.apache.logging.log4j.core.appender.AbstractManager.getManager(AbstractManager.java:75) Apr 21 23:19:58 centos2 logstash: at org.apache.logging.log4j.core.appender.OutputStreamManager.getManager(OutputStreamManager.java:81) Apr 21 23:19:58 centos2 logstash: at org.apache.logging.log4j.core.appender.rolling.RollingFileManager.getFileManager(RollingFileManager.java:103) Apr 21 23:19:58 centos2 logstash: at org.apache.logging.log4j.core.appender.RollingFileAppender.createAppender(RollingFileAppender.java:191) Apr 21 23:19:58 centos2 logstash: ... 86 more Apr 21 23:19:58 centos2 logstash: 2020-04-21 23:19:58,329 main ERROR Null object returned for RollingFile in Appenders. Apr 21 23:19:58 centos2 logstash: 2020-04-21 23:19:58,330 main ERROR Null object returned for RollingFile in Appenders. Apr 21 23:19:58 centos2 logstash: 2020-04-21 23:19:58,331 main ERROR Unable to locate appender "plain_rolling" for logger config "root" Apr 21 23:19:58 centos2 systemd: logstash.service: main process exited, code=exited, status=1/FAILURE Apr 21 23:19:58 centos2 systemd: Unit logstash.service entered failed state. Apr 21 23:19:58 centos2 systemd: logstash.service failed. Apr 21 23:19:58 centos2 systemd: logstash.service holdoff time over, scheduling restart. Apr 21 23:19:58 centos2 systemd: Started logstash. Apr 21 23:19:58 centos2 systemd: Starting logstash... -
同时在logstash自己的日志文件
/var/log/logstash/logstash-plain.log中则没有任何记录,且该文件的属主是root,而logstash进程的属主则是logstash,所以导致启动失败; -
更改
/var/log/logstash/logstash-plain.log文件的属主为logstash:chown logstash /var/log/logstash/logstash-plain.log -
重新启动logstash服务,再次启动失败,查看logstash日志,提示
/var/lib/logstash/queue目录必须可写,这是因为在上一篇的配置测试中,使用root身份前台运行过logstash:[2020-04-21T23:25:28,631][FATAL][logstash.runner ] An unexpected error occurred! {:error=>#<ArgumentError: Path "/var/lib/logstash/queue" must be a writable directory. It is not writable.>, :backtrace=>["/usr/share/logstash/logstash-core/lib/logstash/settings.rb:443:in `validate'", "/usr/share/logstash/logstash-core/lib/logstash/settings.rb:225:in `validate_value'", "/usr/share/logstash/logstash-core/lib/logstash/settings.rb:136:in `block in validate_all'", "org/jruby/RubyHash.java:1343:in `each'", "/usr/share/logstash/logstash-core/lib/logstash/settings.rb:135:in `validate_all'", "/usr/share/logstash/logstash-core/lib/logstash/runner.rb:280:in `execute'", "/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/clamp-0.6.5/lib/clamp/command.rb:67:in `run'", "/usr/share/logstash/logstash-core/lib/logstash/runner.rb:232:in `run'", "/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/clamp-0.6.5/lib/clamp/command.rb:132:in`run'", "/usr/share/logstash/lib/bootstrap/environment.rb:71:in `<main>'"]} [root@centos2 bin]# ls -ld /var/lib/logstash/queue/ drwxr-xr-x 2 root root 6 4月 21 21:11 /var/lib/logstash/queue/ [root@centos2 bin]# ls -l /var/lib/logstash/ 总用量 4 drwxr-xr-x 2 root root 6 4月 21 21:11 dead_letter_queue drwxr-xr-x 2 root root 6 4月 21 21:11 queue -rw-r--r-- 1 root root 36 4月 21 21:38 uuid -
解决该问题,需要将
/var/lib/logstash目录下的所有文件和目录的属主都更改为logstash:chown -R logstash /var/lib/logstash/ -
重启logstash服务,可以看到服务已经正常启动,9600和syslog的10514端口监听也已经正常:
[root@centos2 bin]# netstat -tlnp Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1023/sshd tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1359/master tcp6 0 0 127.0.0.1:9600 :::* LISTEN 4743/java tcp6 0 0 :::3306 :::* LISTEN 1385/mysqld tcp6 0 0 :::10514 :::* LISTEN 4743/java tcp6 0 0 :::22 :::* LISTEN 1023/sshd tcp6 0 0 ::1:25 :::* LISTEN 1359/master [root@centos2 bin]# ps aux |grep logstash logstash 4743 33.0 20.8 3253508 388716 ? SNsl 23:32 0:26 /bin/java -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+DisableExplicitGC -Djava.awt.headless=true -Dfile.encoding=UTF-8 -XX:+HeapDumpOnOutOfMemoryError -Xmx1g -Xms256m -Xss2048k -Djffi.boot.library.path=/usr/share/logstash/vendor/jruby/lib/jni -Xbootclasspath/a:/usr/share/logstash/vendor/jruby/lib/jruby.jar -classpath : -Djruby.home=/usr/share/logstash/vendor/jruby -Djruby.lib=/usr/share/logstash/vendor/jruby/lib -Djruby.script=jruby -Djruby.shell=/bin/sh org.jruby.Main /usr/share/logstash/lib/bootstrap/environment.rb logstash/runner.rb --path.settings /etc/logstash root 4798 0.0 0.0 112724 980 pts/0 R+ 23:33 0:00 grep --color=auto logstash
kibana查看日志
-
数据节点上的logstash正常启动后,到主节点es上可以查看日志是否成功收集;
-
在es上执行
curl '192.168.139.128:9200/_cat/indices?v'查看索引信息:[root@centos_1 ~]# curl '192.168.139.128:9200/_cat/indices?v' health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open system-syslog-2020.04 RxYvkltySdmeHGbTWlr-Zg 5 1 60 0 628.5kb 372.5kb green open .kibana OpdMWp6vTra_HhymSyagOQ 1 1 1 0 7.3kb 3.6kb -
可以看到上面的
systemctl-syslog-2020.04索引,就是我们在配置文件中配置的索引名; -
使用
curl -XGET 'localhost:9200/<indexname>?pretty'可以获取指定索引的详细信息,例如:[root@centos_1 ~]# curl -XGET '192.168.139.128:9200/system-syslog-2020.04?pretty' { "system-syslog-2020.04" : { "aliases" : { }, "mappings" : { "system-syslog" : { "properties" : { "@timestamp" : { "type" : "date" }, "@version" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "facility" : { "type" : "long" }, "facility_label" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "host" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "logsource" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, ... -
curl查看es信息可以参考使用curl命令操作elasticsearch这篇博文;
-
再次到浏览器登录kibana,在主界面的Index pattern表单输入框填入上面查看到的syslog的索引:
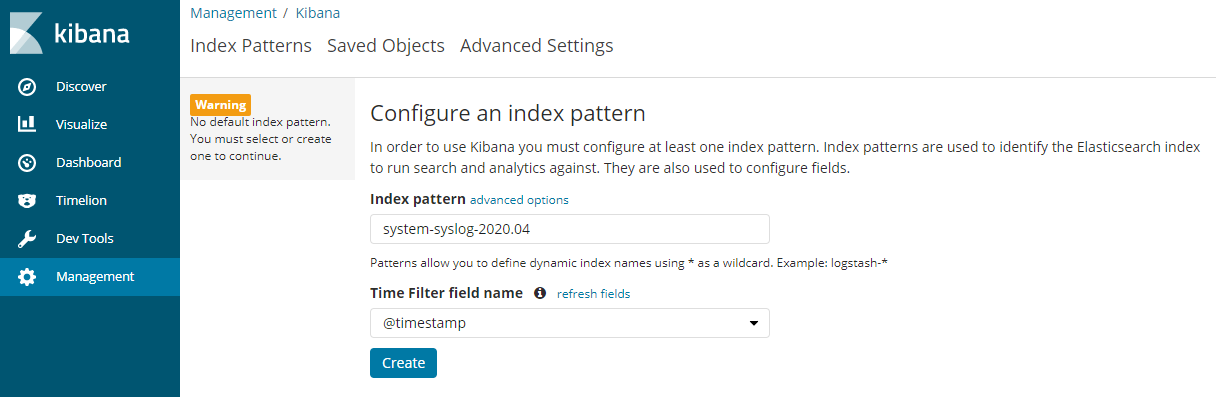
-
这里如果索引填写错误的话,kibana会自动提示错误,同时,因为索引的最后的日期后缀会每个月更新,所以,在kibana填入索引的时候,还可以携程
system-syslog-*这种形式: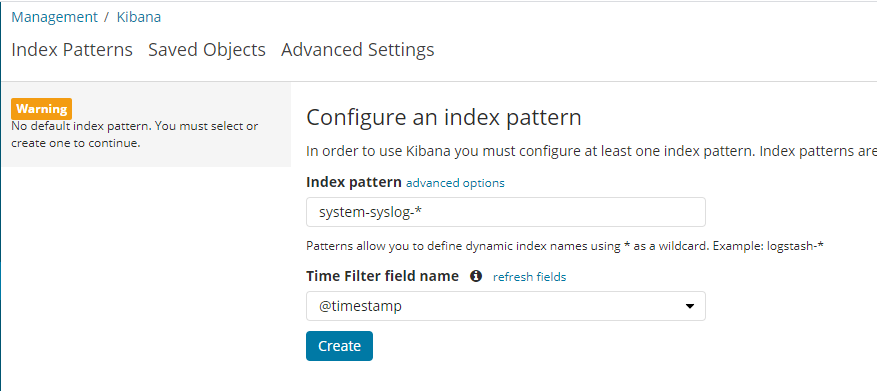
-
然后点击Create按钮,再点击左侧菜单栏的Discover菜单,可以看到我们添加的
system-syslog-*索引,同时右侧显示日志的信息,主要关注其中的message信息: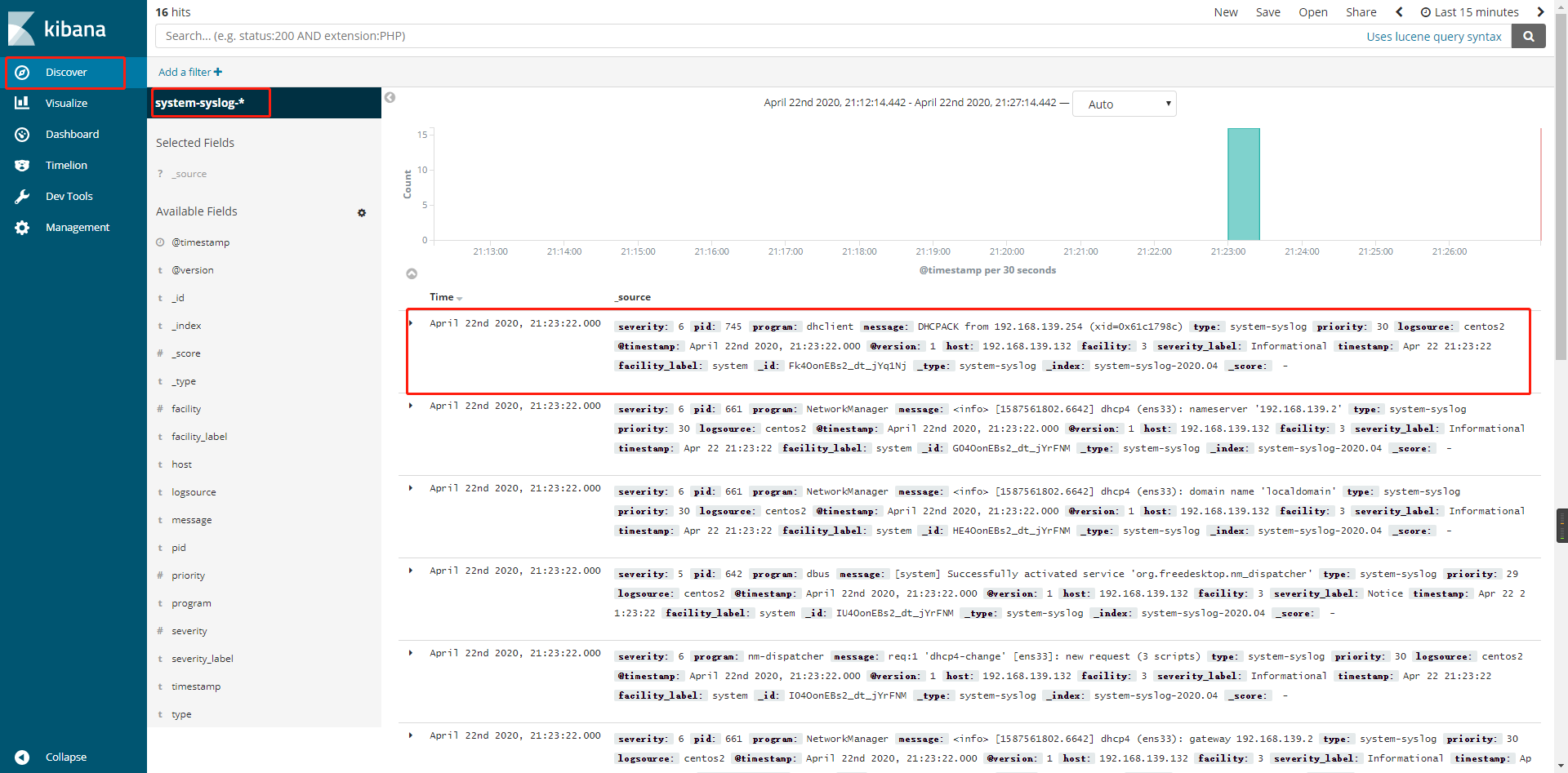
-
这时候我们在132数据节点上执行一些操作,例如登录登出,日志都会在kibana上显示。