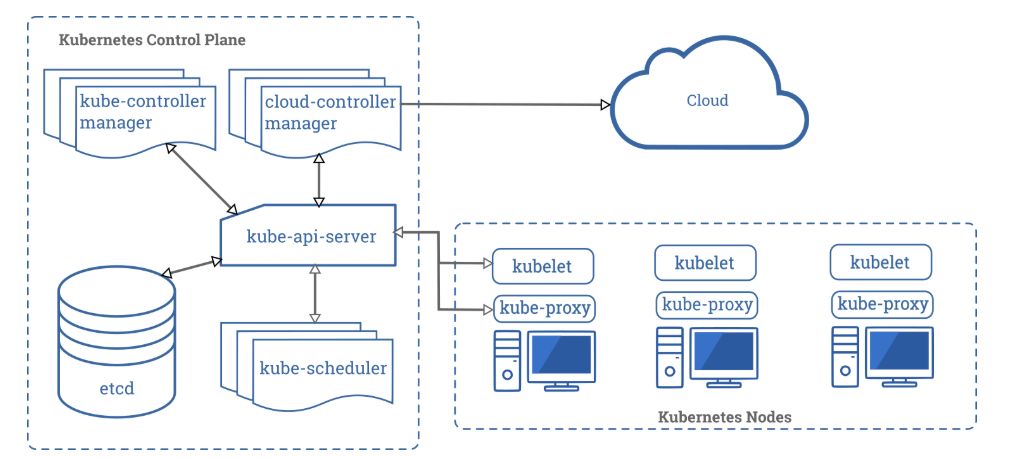
K8S管理命令基础操作配置k8s命令补全,使用yum安装bash-completion软件包;然后执行下面的命令:source /usr/share/bash-completion/bash_completionsource <(ku
从0开始部署K8S,部署准备工作。
使用k8s集群部署LNMP+Discuz程序
1、在kubernetes中使用harbor 2、使用nfs搭建k8s pvc并挂载到pod中